Daten sind das neue Gold, sagt man heute gern. Es wird von Datenobjekten geredet oder vom digitalen Zwilling (digital twin). Es wird unterschieden zwischen Stammdaten, Bestandsdaten und Bewegungsdaten. Um diese Betrachtungen soll es hier erst mal nicht gehen. Hier betrachten wir die Daten an sich, so wie sie technisch abgelegt werden, sodass man gut damit arbeiten kann. Daten sind ungeheuer wichtig. Viele betrachten primär die Programme und reden hier von Optimierungen und Benutzererfahrungen. Aber die Daten mit denen die Programme arbeiten, sind mindestens ebenso wichtig; vielleicht sogar wichtiger. Betrachten wir also einige Aspekte davon.
Eine ungeordnete Ansammlung von Daten nennt man einen Sumpf. So etwas ist natürlich sehr unpraktisch. Das Mindeste, was man damit machen sollte, ist ein Inhaltsverzeichnis anzulegen. Eine einigermaßen geordnete Ablage von unstrukturierten Daten wird See genannt. Diese zusätzlichen Daten, die den Sumpf zum See „veredeln“ werden Meta-Daten genannt.
Für manche Zwecke gibt es hier nicht mehr sehr viel zu tun; oft schon, weil die schiere Datenmenge keine sinnvolle weitere Strukturierung erlaubt. Ein Beispiel dafür sind eingescannte Archive von Zeitschriften. Eine optische Zeichenerkennung OCR ist hier noch sinnvoll, um in dem Text automatisch suchen zu können.
Neu erzeugte Daten wird man besser gleich strukturiert ablegen. Gut geeignet dafür ist oft eine Tabelle. Früher nutzte man dafür gern den Pseudostandard der Komma-separierten Werte CSV. Einerseits ist das für einfache Daten gut umzusetzen, aber man stößt rasch auf Schwierigkeiten, weil der Standard eben nicht wohldefiniert ist. Es werden viele verschiedene Trennzeichen benutzt und auch die Behandlung von Sonderfällen wird nicht einheitlich gehandhabt, wie z.B. Werte behandelt werden, die selbst die Trennzeichen enthalten.
Eine modernere Möglichkeit ist die Extensible Markup Language XML. Sie erlaubt praktisch beliebige Daten ordentlich strukturiert abzulegen. Sonderzeichen werden einheitlich als sogenannte Entität abgelegt. Die genaue Struktur eines XML kann selbst wieder in einem speziellen XML-Format beschrieben werden, einer XML Schema Definition XSD. Auf diese Weise kann ein XML automatisch geschrieben, gelesen und auf Gültigkeit geprüft werden. Anders gesagt, das XML erklärt und definiert sich gewissermaßen selbst. Viele Office-Dateiformate sind davon abgeleitet. Auch das Vektor-Grafik-Format Scalable Vector Graphics SVG beruht auf XML.
Besonders auf interaktiven Webseiten müssen häufig je nach Benutzereingabe Daten vom Server nachgeladen werden. Traditionell war es dafür nötig, die Webseite komplett neu zu laden. Heute werden diese Daten dynamisch per Asynchronous JavaScript and XML AJAX nachgeladen. Entgegen der Aussage der Abkürzung erfolgt das heute meist nicht mehr in XML, sondern im Datenformat der Programmiersprache der Webbrowser, also Javascript. Dieses Datenformat wird JavaScript Object Notation JSON genannt.
JSON ist recht beliebt für den Datenaustausch und wird auch gern von Webservices genutzt. Theoretisch könnte man JSON direkt wie eine Sammlung von Variablen in JavaScript einlesen. Dafür müsste man aber die exec-Funktion nutzen. Dieses Feature steht prinzipiell in jeder Skriptsprache zur Verfügung, wird aber aus Sicherheitsgründen kaum noch genutzt. Exec würde auch Befehle ausführen, könnte also einfach zum Einschleusen von Schadcode missbraucht werden. Daher nutzt man spezielle Funktionen zum Kodieren und Dekodieren von JSON, die heute in vielen Programmiersprachen zur Verfügung stehen.
Möchte man große Datenmengen geordnet ablegen und verarbeiten, wird man das gewöhnlich in einer Datenbank tun. Es lohnt sich beim Design einer Datenbank einige Gedanken über die sogenannte Normalisierung der Daten zu machen. Die wichtigsten Grundregeln sind zum einen, dass die abgelegten Daten für die Verarbeitung nicht mehr weiter zerlegt werden sollen. Sie werden in sogenannten Atomen abgelegt und später zu größeren Ergebnissen zusammengefasst. Zum anderen werden Daten immer eindeutig abgelegt. So wird man z.B. die Information, dass zum Call DL1KLM der Name des OMs Hans ist nur ein Mal in der Datenbank anlegen und nicht bei jedem einzelnen QSO. Der Sinn ist, dass so Redundanzen, die zu Inkonsistenzen führen können, vermieden werden.
Damit das funktioniert, müssen die Daten auch wieder verknüpft werden können. In einer Tabelle werden die QSOs mit Call abgelegt und in einer anderen Tabelle stehen die Namen und weitere Informationen zum Call. Die Verknüpfung zwischen den beiden Tabellen erfolgt über Entity Relations. Dazu wird das Rufzeichen in der Tabelle mit den weiteren Daten zum Primärschlüssel ernannt. Dieser Schlüssel ist eindeutig und stellt so sicher, dass die Daten zum Call eindeutig sind. In der Tabelle der QSO ist das Rufzeichen ein Fremdschlüssel. Das stellt sicher, dass es das Rufzeichen in der anderen Tabelle auch gibt. In der zur Datenbank zugehörigen Applikation wird man das dann so umsetzen, dass der Eintrag eines neuen Rufzeichens ggf. automatisch erzeugt wird, wenn ein QSO eine Erstverbindung ist.
Es gibt viele Arten, Daten abzulegen. Und es gibt viele Dinge dabei zu beachten. Historisch wurden viele Dinge ausprobiert. Ein bekanntes Beispiel sind Zeichensätze. Heute wird man meist Varianten von Unicode nutzen, wie UTF-8 oder UCS-2. Zum Umwandeln von anderen Zeichensätzen kann man automatische Konverter benutzen. Eine andere früher weit verbreite Art Daten abzulegen, waren Dateien mit festen Feldlängen. In perfekt definierten Datensätzen kann das funktionieren, aber es kommt leicht zu Problemen, wenn die beteiligten Programme nicht gut mit dem Überschreiten der Feldlänge umgehen konnten. Das ist besonders tückisch, wenn abgeschnittene Daten keinen Sinn mehr ergeben, wie z.B. oben erwähnte HTML-Entitys oder sonst kodierte Daten.
Bildformate
Die üblichen Bildformate wie JPEG und PNG und auch die alten wie GIF und BMP können mit normalen Programmen zur Bildverarbeitung wie GIMP geöffnet, bearbeitet und konvertiert werden. Gelegentlich kommt man aber an proprietäre Formate, die nicht automatisch erkannt werden; wie z.B. die in Funkgeräten abgelegten Bilder für den Splash-Screen beim Booten oder für den Hintergrund. Das sind oft „rohe“ Datenformate, die 1:1 die Pixel auf dem Display repräsentieren. Hier hilft es, wenn ein paar Metadaten bekannt sind, wie z.B. die Auflösung des Displays oder wenigstens das Seitenverhältnis. Dazu kennen wir die Größe der Datei in Byte.
Nehmen wir als Beispiel hier die .bin-Datei vom Boot-Image eines Anytone 878. Sie hat 40960 Bytes. Den Bildschirm messen wir zu 35mm x 28mm und erhalten so ein Seitenverhältnis von 4:5. Die lange Seite x berechnet sich in Pixel zu:
$$ x * 4/5 \, * x = 40960 $$
$$ x = \sqrt{5/4 * 40960} = 226{,}3 $$
Das geht also so nicht auf. Da wir hier gewissermaßen Reverse-Engineering betreiben, müssen wir ein paar Dinge raten. Eine plausible Annahme ist hier, dass ein Pixel in mehreren Bytes abgelegt wird. Probieren wir also 2 Byte/Pixel und rechnen mit 40960 Bytes / 2 Byte/Pixel = 20480 Pixel:
$$ x * 4/5 \, x = 20480 $$
$$ x = \sqrt{5/4 * 20480} = 160 $$
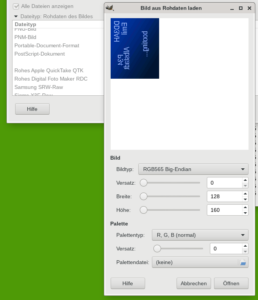
Und die kurze Seite ist dann 160 * 4/5 = 128. Das sind also nun plausible Werte. Mit diesem Wissen können wir die Daten z.B. „roh“ in Gimp einlesen. Dazu gehen wir in den normalen Öffnen-Dialog und nutzen nicht das üblicherweise gesetzte Feature „Dateityp automatisch bestimmen“ , sondern scrollen hier runter bis „Rohdaten des Bildes“. Dazu muss noch der Haken bei „Alle Dateien anzeigen“ gesetzt werden, um die .bin-Datei zum Laden auswählen zu können.
Geben wir nun als Breite 160 und als Höhe 128 ein. Und dazu wählen wir einen Bildtyp mit 16 Bit, wie z.B. RGB565 Big-Endian. Hier werden für Rot, Grün und Blau 5, 6 und 5 Bit pro Pixel genutzt, in Summe als 16 Bit oder 2 Byte, so wie oben von uns ermittelt.
Bei der Auswahl des richtigen Bildtyps kann es nützlich sein, das Bild vom Display des Geräts zu kennen. Zumindest die Farben des Bildes sollten nun passen. Aber das Bild bleibt verwürfelt. Es gibt noch einen Freiheitsgrad, den wir ausprobieren müssen: Die „technische Anordnung“ der Pixel muss nicht unbedingt der normalen Betrachtungsrichtung des Displays entsprechen.
Es gibt Displays bei denen die Pixel nicht quadratisch sind. Hier ist es sehr schwer, die Auflösung zu erraten. In solchen fällen muss man mit dem Schieberegler für die Breite langsam und gefühlvoll ein paar Werte ausprobieren. Mit ein bisschen Geschick findet man so auch die passenden Zahlenwerte.
Wir probieren also eine Breite von 128 und eine Höhe von 160 aus. Jetzt können wir das Bild schon erkennen und wir laden es so. Wir nutzen im Menü Bild von Gimp noch die Transformation um 90° drehen und Horizontal spiegeln.
Jetzt haben wir das Bild so wie es im Gerät angezeigt wird und können es in einem normalen Bildformat wie PNG speichern.